I’ve spent much of my career working with relational databases such as Oracle and MySQL, and SQL performance has always been an area of focus for me. I’ve spent countless hours reviewing EXPLAIN plans, rewriting subqueries, adding new indexes, and chasing down table-scans. I’ve been trained to make performance improvements such as: only choose columns in a SELECT that are absolutely necessary, stay away from LIKE clauses, review the cardinality of columns before adding indexes, and always JOIN on indexed columns.
It’s been an instinctual part of my life as a Database Administrator who supports OLTP databases that have sold in excess of 20K tickets per minute to your favorite events. I remember a specific situation where a missing index caused our production databases to get flooded with table-scans that brought a world-wide on-sale to an immediate halt. I had a lot of explaining to do that day as the missing index made it to QA and Stage but not Production!
In recent years, I’ve transitioned to Data Engineering and began supporting Big Data environments. Specifically, I’m supporting Eventbrite’s Data Warehouse which leverages Presto and Apache Hive using the Presto/Hive connector. The data files can be of different formats, but we’re using HDFS and S3. The Hive metadata describes how data stored in HDFS/S3 maps to schemas, tables, and columns to be queried via SQL. We persist this metadata information in Amazon Aurora and access it through the Presto/Hive connector via the Hive Metastore Service (HMS).
The stakes have changed and so have the skill-sets required. I’ve needed to retrain myself in how to write optimal SQL for Presto. Some of the best practices for Presto are the same as relational databases and others are brand new to me. This blog post summarizes some of the similarities and some of the differences with writing efficient SQL on MySQL vs Presto/Hive. Along the way I’ve had to learn new terms such as “federated queries”, “broadcast joins”, “reshuffling”, “join reordering”, and “predicate pushdown”.
Let’s start with the basics:
What is MySQL? The world’s most popular open source database. The MySQL software delivers a fast, multi-threaded, multi-user, and robust SQL (Structured Query Language) database server. MySQL is intended for mission-critical, heavy-load production database usage.
What is Presto? Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto doesn’t use the map reduce framework for its execution. Instead, Presto directly accesses the data through a specialized distributed query engine that is very similar to those found in commercial parallel relational databases.
Presto uses ANSI SQL syntax/semantics to build its queries. The advantage of this is that analysts with experience with relational databases will find it very easy and straightforward to write Presto queries! That said, the best practices for developing efficient SQL via Presto/Hive are different from those used to query standard RDBMS databases.
Let’s transition to Presto performance tuning tips and how they compare to standard best practices with MySQL.
1. Only specify the columns you need
Restricting columns for SELECTs can improve your query performance significantly. Specify only needed columns instead of using a wildcard (*). This applies to Presto as well as MySQL!
2. Consider the cardinality within GROUP BY
When using GROUP BY, order the columns by the highest cardinality (that is, most number of unique values) to the lowest.
The GROUP BY operator distributes rows based on the order of the columns to the worker nodes, which hold the GROUP BY values in memory. As rows are being ingested, the GROUP BY columns are looked up in memory and the values are compared. If the GROUP BY columns match, the values are then aggregated together.
3. Use LIMIT with ORDER BY
The ORDER BY clause returns the results of a query in sort order. To process the sort, Presto must send all rows of data to a single worker and then sort them. This sort can be a very memory-intensive operation for large datasets that will put strain on the Presto workers. The end result will be long execution times and/or memory errors.
If you are using the ORDER BY clause to look at the top N values, then use a LIMIT clause to reduce the cost of the sort significantly by pushing the sorting/limiting to individual workers, rather than the sorting being done by a single worker.
I highly recommend you use the LIMIT clause not just for SQL with ORDER BY but in any situation when you’re validating new SQL. This is good practice for MySQL as well as Presto!
4. Using approximate aggregate functions
When exploring large datasets often an approximation (with standard deviation of 2.3%) is more than good enough! Presto has approximate aggregation functions that give you significant performance improvements. Using the approx_distinct(x) function on large data sets vs COUNT(DISTINCT x) will result in performance gains.
When an exact number may not be required―for instance, if you are looking for a rough estimate of the number of New Years events in the Greater New York area then consider using approx_distinct(). This function minimizes the memory usage by counting unique hashes of values instead of entire strings. The drawback is that there is a small standard deviation.
5. Aggregating a series of LIKE clauses in one single regexp_like clause
The LIKE operation is well known to be slow especially when not anchored to the left (i.e. the search text is surrounded by ‘%’ on both sides) or when used with a series of OR conditions. So it is no surprise that Presto’s query optimizer is unable to improve queries that contain many LIKE clauses.
We’ve found improved LIKE performance on Presto by substituting the LIKE/OR combination with a single REGEXP_LIKE clause, which is Presto native. Not only is it easier to read but it’s also more performant. Based on some quick performance tests, we see ~30% increase in run-times with REGEXP_LIKE vs comparable LIKE/OR combination.
For example:
SELECT ...FROM zoo WHERE method LIKE '%monkey%' OR method LIKE '%hippo%' OR method LIKE '%tiger%' OR method LIKE '%elephant%'
can be optimized by replacing the four LIKE clauses with a single REGEXP_LIKE clause:
SELECT ...FROM zoo WHERE REGEXP_LIKE(method, 'monkey|hippo|tiger|elephant')
6. Specifying large tables first in join clause
When joining tables, specify the largest table first in the join. The default join algorithm of Presto is broadcast join, which partitions the left-hand side table of a join and sends (broadcasts) a copy of the entire right-hand side table to all of the worker nodes that have the partitions. If the right-hand side table is “small” then it can be replicated to all the join workers which will save CPU and network costs. This type of join will be most efficient when the right-hand side table is small enough to fit within one node.
If you receive an ‘Exceeded max memory’ error, then the right-hand side table is too large. Presto does not perform automatic join-reordering, so make sure your largest table is the first table in your sequence of joins.
This was an interesting performance tip for me. As we know, SQL is a declarative language and the ordering of tables used in joins in MySQL, for example, is *NOT* particularly important. The MySQL optimizer will re-order to choose the most efficient path. With Presto, the join order matters. You’ve been WARNED! Presto does not perform automatic join-reordering unless using the Cost Based Optimizer!
7. Turning on the distributed hash join
If you’re battling with memory errors then try a distributed hash join. This algorithm partitions both the left and right tables using the hash values of the join keys. So the distributed join works even if the right-hand side table is large, but the performance might be slower because the join increases the number of network data transfers.
At Eventbrite we have the distributed_join variable set to ‘true’. (SHOW SESSION). Also it can be enabled by setting a session property (set session distributed_join = ‘true’).
8. Partition your data
Partitioning divides your table into parts and keeps the related data together based on column values such as date or country. You define partitions at table creation, and they help reduce the amount of data scanned per query, thereby improving performance.
Here are some hints on partitioning:
- Columns that are used as WHERE filters are good candidates for partitioning.
- Partitioning has a cost. As the number of partitions in your table increases, the higher the overhead of retrieving and processing the partition metadata, and the smaller your files. Use caution when partitioning and make sure you don’t partition too finely.
- If your data is heavily skewed to one partition value, and most queries use that value, then the overhead may wipe out the initial benefit.
A key partition column at Eventbrite is transaction date (txn_date).
CREATE TABLE IF NOT EXISTS fact_ticket_purchase ( ticket_id STRING, .... create_date STRING, update_date STRING ) PARTITIONED BY (trx_date STRING) STORED AS PARQUET TBLPROPERTIES ('parquet.compression'='SNAPPY')
9. Optimize columnar data store generation
Apache Parquet and Apache ORC are popular columnar data stores. They provide features that store data efficiently by using column-wise compression based on data type, special encoding, and predicate pushdown. At Eventbrite, we define Hive tables as PARQUET using compression equal to SNAPPY….
CREATE TABLE IF NOT EXISTS dim_event ( dim_event_id STRING, .... create_date STRING, update_date STRING, ) STORED AS PARQUET TBLPROPERTIES ('parquet.compression'='SNAPPY')
Apache Parquet is an open-source, column-oriented data storage format. Snappy is designed for speed and will not overload your CPU cores. The downside of course is that it does not compress as well as gzip or bzip2.
10. Presto’s Cost-Based Optimizer/Join Reordering
We’re not currently using Presto’s Cost-Based Optimizer (CBO)! Eventbrite data engineering released Presto 330 in March 2020, but we haven’t tested CBO yet.
CBO inherently requires the table stats be up-to-date which we only calculate for a small subset of tables! Using the CBO, Presto will be able to intelligently decide the best sequence based on the statistics stored in the Hive Metastore.
As mentioned above, the order in which joins are executed in a query can have a big impact on performance. If we collect table statistics then the CBO can automatically pick the join order with the lowest computed costs. This is governed by the join_reordering_strategy (=AUTOMATIC) session property and I’m really excited to see this feature in action.
Another interesting join optimization is dynamic filtering. It relies on the stats estimates of the CBO to correctly convert the join distribution type to “broadcast” join. By using dynamic filtering via run-time predicate pushdown, we can squeeze out more performance gains for highly-selective inner-joins. We look forward to using this feature in the near future!
11. Using WITH Clause
The WITH clause is used to define an inline view within a single query. It allows for flattening nested subqueries. I find it hugely helpful for simplifying SQL, and making it more readable and easier to support.
12. Use Presto Web Interface
Presto provides a web interface for monitoring queries (https://prestodb.io/docs/current/admin/web-interface.html).
The main page has a list of queries along with information like unique query ID, query text, query state, percentage completed, username and source from which this query originated. If Presto cluster is having any performance-related issues, this web interface is a good place to go to identify and capture slow running SQL!

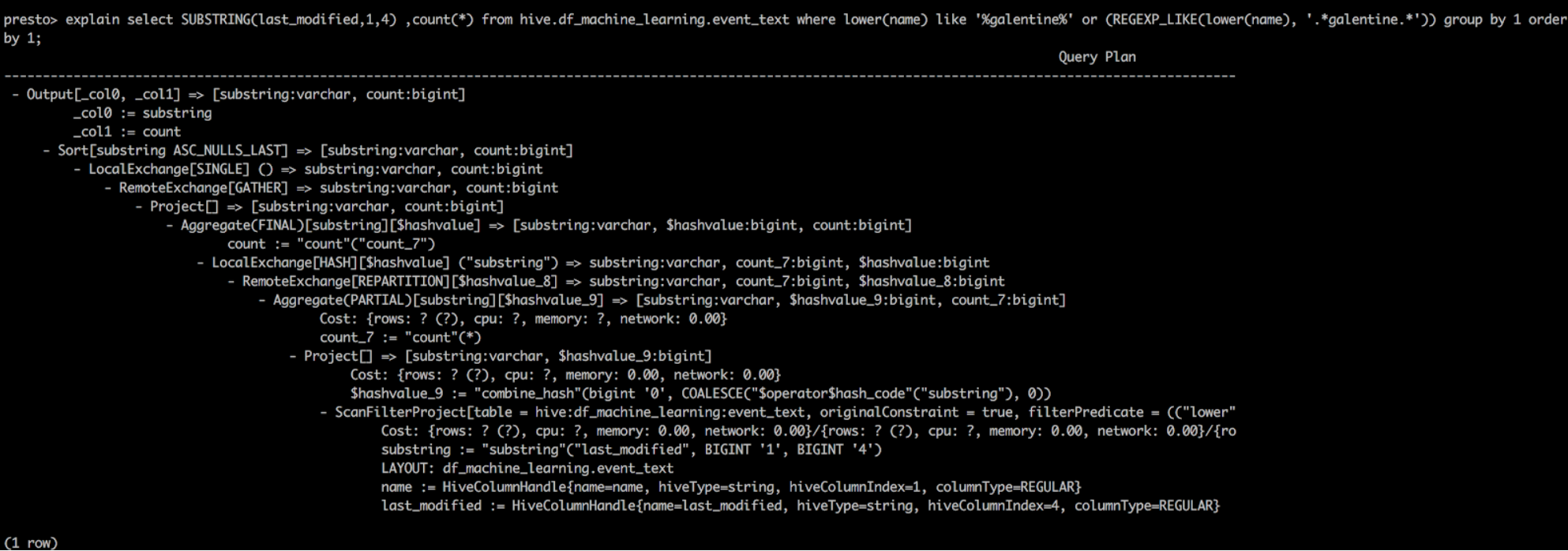
13. Explain plan with Presto/Hive (Sample)
EXPLAIN is an invaluable tool for showing the logical or distributed execution plan of a statement and to validate the SQL statements.
— Logical Plan with Presto
explain select SUBSTRING(last_modified,1,4) ,count(*) from hive.df_machine_learning.event_text where lower(name) like ‘%wilbraham%’ or (REGEXP_LIKE(lower(name), ‘.*wilbraham.*’)) group by 1 order by 1;
14. Explain plan with MySQL (Sample)

In this particular case you can see that the primary key is used on the ‘ejp_events’ table and the non-primary key on the “ejp_orders’ table. This query is going to be fast!
Conclusion
Presto is the “SQL-on-Anything” solution that powers Eventbrite’s data warehouse. It’s been very rewarding for me as the “Old School DBA” to learn new SQL tricks related to a distributed query engine such as Presto. In most cases, my SQL training on MySQL/Oracle has served me well but there are some interesting differences which I’ve attempted to call-out above. Thanks for reading and making it to the end. I appreciate it!
We look forward to giving Presto’s Cost-Based Optimizer a test drive and kicking the tires on new features such as dynamic filtering & partition pruning!
All comments are welcome, or you can message me at ed@eventbrite.com. You can learn more about Eventbrite’s use of Presto by checking out my previous post at Boosting Big Data workloads with Presto Auto Scaling.
Special thanks to Eventbrite’s Data Foundry team (Jeremy Bakker, Alex Meyer, Jasper Groot, Rainu Ittycheriah, Gray Pickney, and Beck Cronin-Dixon) for the world-class Presto support, and Steven Fast for reviewing this blog post. Eventbrite’s Data Teams rock!