The Data Engineering team at Eventbrite recently completed several significant improvements to our data ecosystem. In particular, we focused on upgrading our data warehouse infrastructure and improving the tools used to drive Eventbrite’s data-driven analytics.
Here are a few highlights:
- Transitioned to a new Hadoop cluster. The result is a more reliant, secure, and performant data warehouse environment.
- Upgraded to the latest version of Tableau and migrated our Tableau servers to the same AWS infrastructure as Presto. We also configured Tableau to connect via its own dedicated Presto cluster. The data transfer rates, especially for Tableau extracts, are 10x faster!
- We upgraded Presto and fine-tuned the resource allocation (via AWS Auto Scaling) to make the environment optimal for Eventbrite’s analysts. Presto is now faster and more stable. Our daily Tableau dashboards, as well as our ad-hoc SQL queries, are running 2 to 4 times faster.
This post focuses on how Eventbrite leverages AWS Auto Scaling for Presto using Auto Scaling Groups, Scaling Policies, and Launch Configurations. This update has allowed us to meet the data exploration needs of our Engineers, Analysts, and Data Scientists by providing better throughput at a fraction of the cost.
High level overview
Let’s start with a high-level view of our data warehouse environment running on AWS.
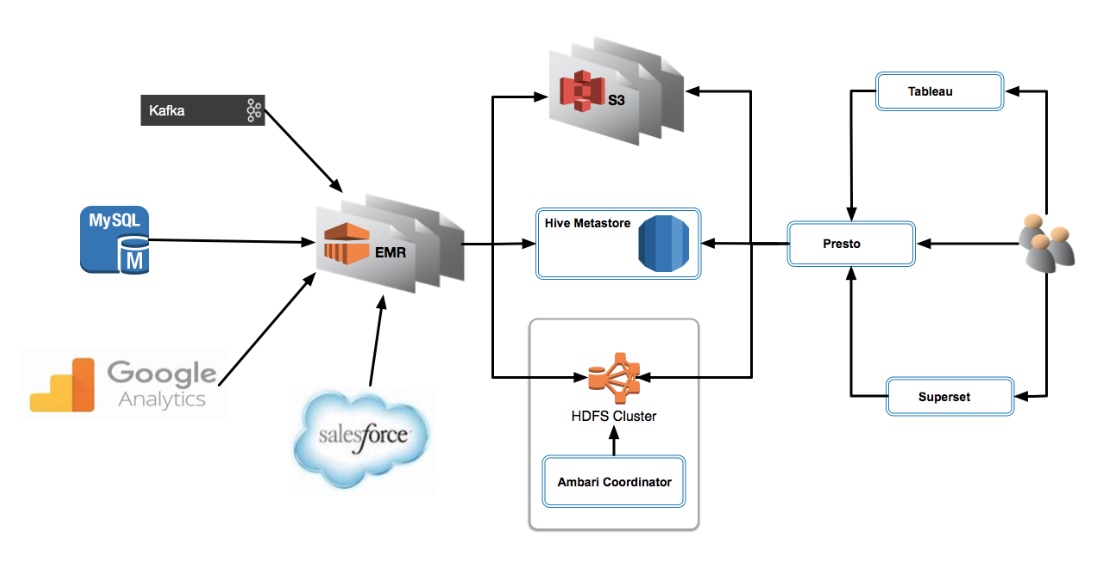

Analytics tools: Presto, Superset and Tableau
We’re using Presto to access data in our data warehouse. Presto is a tool designed to query vast amounts of data using distributed queries. It supports the ANSI SQL standard, including complex queries, aggregations, and joins. The Presto team designed it as an alternative to tools that query HDFS using pipelines of MapReduce jobs. It connects to a Hive Metastore allowing users to share the same data with Hive, Spark, and other Hadoop ecosystem tools.
We’re also using Apache Superset packaged alongside Presto. Superset is a data exploration web application that enables users to process data in a variety of ways including writing SQL queries, creating new tables and downloading data in CSV format. Among other tools, we rely heavily on Superset’s SQL Lab IDE to explore and preview tables in Presto, compose SQL queries, and save output files as CSV.
We’re exploring the use of Superset for dashboard prototyping although currently the majority of our data visualization requirements are being met by Tableau. We use Tableau to represent Eventbrite’s data in dashboards that are easily digestible by the business.
The advantage of Superset is that it’s open-source and cost-effective, although we have performance concerns due to lack of caching and it’s missing some features (triggers on charts, tool-tips, support for non-SQL functions, scheduling) that we would like to see. We plan to continue to leverage Tableau as our data visualization tool, but we also plan to adopt more Superset usage in the future.
Both Tableau and Superset connect to Presto, which retrieves data from Hive tables located on S3 and HDFS commonly stored as Parquet.
Auto scaling overview
Amazon EC2 Auto Scaling enables us to follow the demand curve for our applications, and thus reduces the need to manually provision Amazon EC2 capacity in advance. For example, we can use target tracking scaling policies to select a load metric for our application, such as CPU utilization or via the Presto metrics.
It’s critical to understand the terminology for AWS Auto Scaling. Tools such as “Launch Configuration,” “Auto Scaling Group” and “Auto Scaling Policy” are vital components we show below. Here is a diagram that shows the relationship between the main components of AWS Auto Scaling. As an old-school data modeler, I tend to think in terms of entities and relationships via the traditional ERD model 😀
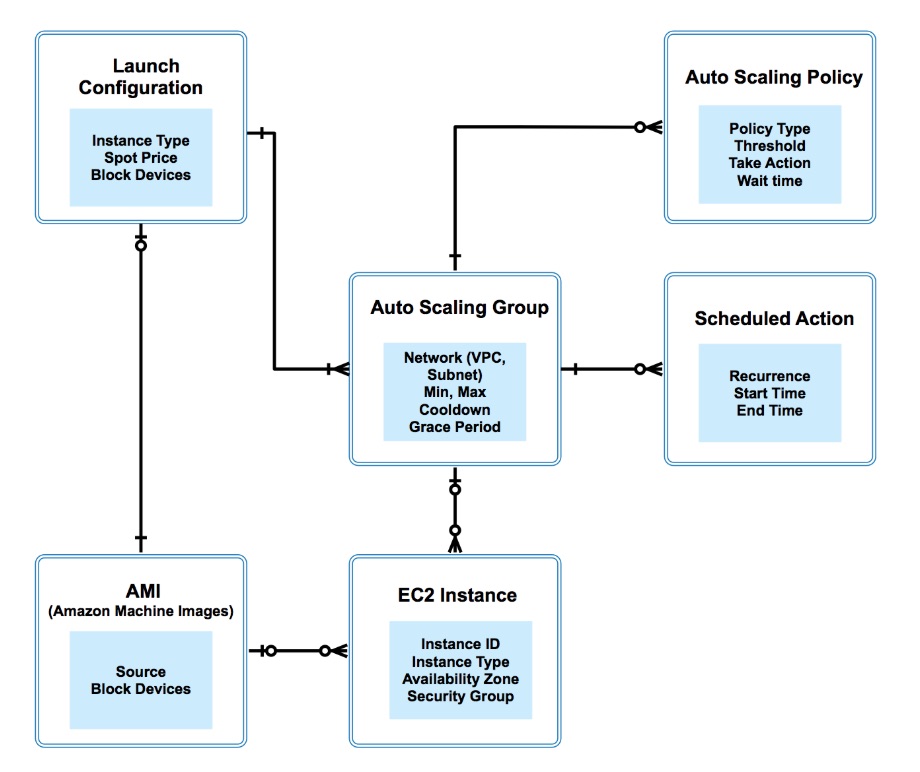
Presto auto scaling
We’re using AWS Auto Scaling for our Presto “spot” instances based on (I) CPU usage and (II) number of queries (only used for scaledown). Here is an overview of our EC2 auto-scaling setup for Presto.
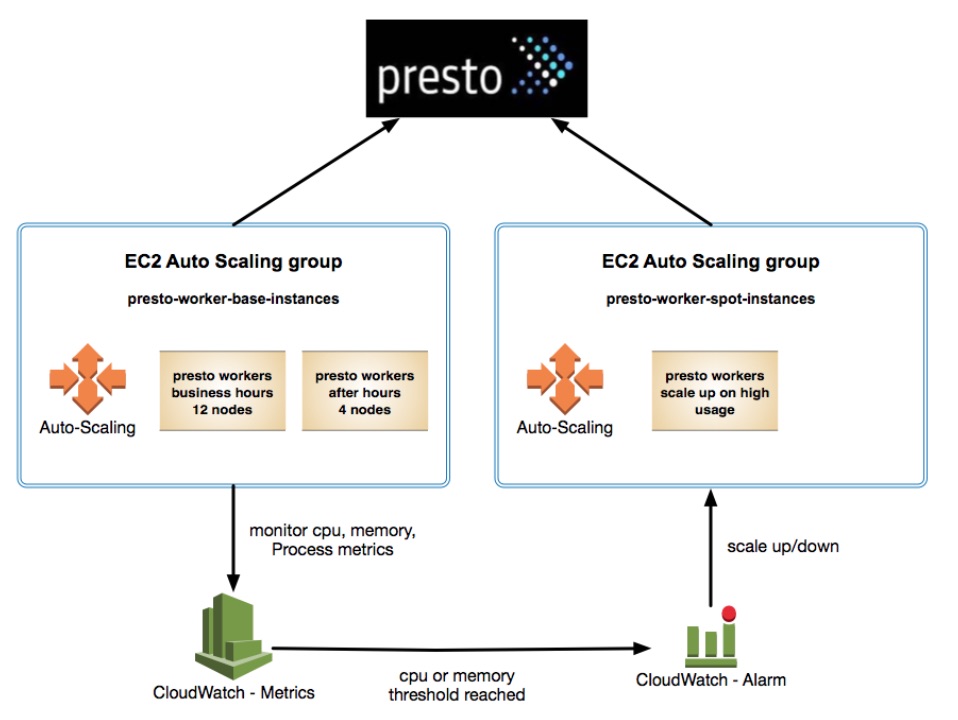
Here are some sample policies:
Policy type: Simple scaling (I)
Execute policy when: CPU Utilization >= 50 for 60 seconds for the metric dimensions .
Take the action: Add 10 instances (provided by EC2).
Policy type: Simple scaling (II)
Execute policy when: running Queries <= 0 for 2 consecutive periods of 300 seconds for the metric dimensions.
Take the action: Set to 0 instances.
Note: A custom Python script was developed by Eventbrite’s Data Engineering team to handshake with Cloudwatch concerning scaledown. It handles the race condition where another query comes in during the scaledown process. We’ve added “termination protection” which leverages this Python script (running as a daemon) on each Presto worker node. If it detects a query is currently running on this node, then it won’t scale down.
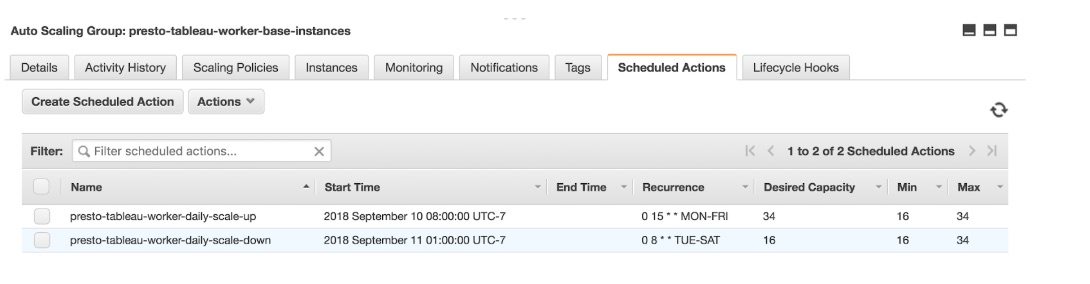
Tableau scheduled actions
We’re using “Scheduled Scaling” features for our Tableau Presto instances as well as our “base” instances used for Presto. We scale up the instances in the morning and scale down at night. We’ve set up scheduled scaling based on predictable workloads such as Tableau.
“Scheduled Scaling” requires configuration of scheduled actions, which tells Amazon EC2 Auto Scaling to act at a specific time. For each scheduled action, we’ve specified the start time, and the new minimum, maximum, and the desired size of the group. Here is a sample setup for scheduled actions:
Cloudwatch
We’ve enabled Auto Scaling Group Metrics to identify capacity changes via CloudWatch alarms. When triggered, these alarms will cause autoscaling groups to execute the policy when a threshold is breached. In some cases, we’re using EC2 alerts and in others, we’re pushing custom metrics through python scripts to Cloudwatch.
Sample Cloudwatch alarms:

Multiple Presto clusters
We’ve separated Tableau connections from ad-hoc Presto connections. This abstraction allows us to separate ad-hoc query usage from Tableau usage.

EMR
Our Presto workers read data that is written by our persistent EMR clusters. Our ingestion and ETL jobs run on daily and hourly scheduled EMR clusters with access to Spark, Hive and Sqoop. Using EMR allows us to decouple storage from computation by using a combination of S3 and a custom HDFS cluster. The key is we only pay for computation when we use it!
We have multiple EMR clusters that write the data to Hive tables backed by S3 and HDFS. We launch EMR clusters to run our ETL processes that load our data warehouse tables daily/hourly. We don’t currently tie our EMR clusters to auto-scaling.
By default, EMR stores Hive Metastore information in a MySQL database on the master node. It is the central repository of Apache Hive metadata and includes information such as schema structure, location, and partitions. When a cluster terminates, we lose the local data because the node file systems use ephemeral storage. We need the Metastore to persist, so we’ve created an external Metastore that exists outside the cluster.
We’re not using the AWS Glue Data Catalog. The Data Engineering team at Eventbrite is happy managing our Hive Metastore on Amazon Aurora. If something breaks, like we’ve had in the past with Presto race conditions writing to the Hive Metastore, then we’re comfortable fixing it ourselves.
The Data Engineering team created a persistent EMR single node “cluster” used by Presto to access Hive. Presto is configured to read from this cluster to access the Hive Metastore. The Presto workers communicate with the cluster to relay where the data lives, partitions, and table structures.
The end
In summary, we’ve focused on upgrading our data warehouse infrastructure and improving the tools used to drive Eventbrite’s data-driven analytics. AWS Auto Scaling has allowed us to improve efficiency for our analysts while saving on cost. Benefits include:
Decreased Costs
AWS Auto Scaling allows us to only pay for the resources we need. When demand drops, AWS Auto Scaling removes any excess resource capacity, so we avoid overspending.
Improved Elasticity
AWS Auto Scaling allows us to dynamically increase and decrease capacity as needed. We’ve also eliminated lost productivity due to non-trivial error rates caused by failed queries due to capacity issues.
Improved Monitoring
We use metrics in Amazon CloudWatch to verify that our system is performing as expected. We also send metrics to CloudWatch that can be used to trigger AWS Auto Scaling policies we use to manage capacity.
All comments are welcome, or you can message me at ed@eventbrite.com. Thanks to Eventbrite’s Data Engineering crew (Brandon Hamric, Alex Meyer, Beck Cronin-Dixon, Gray Pickney and Paul Edwards) for executing on the plan to upgrade Eventbrite’s data ecosystem. Special thanks to Rainu Ittycheriah, Jasper Groot, and Jeremy Bakker for contributing/reviewing this blog post.
You can learn more about Eventbrite’s data infrastructure by checking out my previous post at Looking under the hood of the Eventbrite data pipeline.
Wow, That’s really great information for us. Its very helpful and gives us proper knowledge about big data. so, thank you very much for providing us this kind of information.
Such a really very nice post