Eventbrite’s React applications are a single React app with many entry points. To improve the development experience for both backend and frontend engineers, we implemented a single application mode (codenamed SAM) in our local environments. Whenever the React Docker container boots, it downloads and statically serves a set of pre-built assets for all of the React applications so that Webpack compilation never has to run.
Using a settings file, developers can indicate that they would like to run only their app in an active development mode. Having this feature was another significant milestone towards the quest for micro-apps. Backend engineers no longer have to wait for Webpack to set up to compile and recompile files that they will never change, and frontend developers only need to run Webpack for their app.
The post you are reading is the second in a series entitled The Quest for Micro-Apps detailing how our Frontend Platform team is decoupling our React apps from themselves and our Django monolith application. We are going to do it by creating Micro-Apps so that we can develop and deploy independently. If you haven’t already, check out the Introduction that provided background and overall goals for the project.

A little background
Our React apps are universal apps: they render both client-side in the browser and server-side in Node. Also, as mentioned in the introduction, we have just one single React application with an entry point for every app, which is how we get the different bundles to use for the different apps.
We use Docker for our development environment, which runs many, many containers to spin up a local version of all of eventbrite.com. One of these containers is our React container that contains all of the React apps. When the container starts, it spawns two Webpack processes that watch for source code changes. The server-side render requests consume the Node bundles that the first task writes to disk. The second process is a webpack-dev-server process, which creates in-memory bundles and reloads the page once new changes are compiled.
The growth problem
This setup worked fine when we initially created this infrastructure over a year ago, and we had less than a dozen apps; the processes ran quickly and development felt very responsive. However, a year later, the number of apps had nearly tripled, and the development environment was starting to feel sluggish, not only for the frontend developers who are living in React-land but also for the backend developers who never touch our React stack.
Our backend engineers developing APIs, working on the monolith, or merely browsing the site locally were spawning those same two Webpack watchers even though they weren’t making any JavaScript changes. Our backend devs were also waiting for the Webpack processes to perform their initial compilation at container start, which wasted a good amount of time. The container was also eating up a lot of memory watching for file changes that would never happen. Backend devs didn’t need Webpack running at all, just for the local site to work.
It was not just the backend devs who were hurting. Because all of the React apps were just a single app with many entry points, we were recompiling the entire app every time a change happened. When a dev made a change to their app, Webpack had to follow all of the other 29 entry points to see if their Node and webpack-dev-server bundles needed to be recreated as well. Why should they have to wait when they only cared about changes to their app? Webpack is smart about knowing what has changed, but it was still doing a whole lot of unnecessary work. Furthermore, at the container start, we were still waiting for the initial Webpack compilation to build all of the other apps, in addition to the one we were working on.
Static apps to the rescue
Our proposed solution was to enable a “static mode” in our development environment. By default, everyone would load the same bundled assets that are used in our continuous integration (CI) server. In this case, we wouldn’t need webpack-dev-server running; we could use a simple static Express server for serving assets. This new approach would greatly benefit our backend engineers who weren’t writing React code.
A developer would have to opt-in to run their app(s) in “dynamic mode.” However, the Webpack processes would only watch specific app(s), significantly reducing the amount of work they would need to do. This approach would greatly benefit our frontend engineers who were working on only an app or two at a time.
Single Application Mode (codenamed SAM) also fit into our long-term strategy of micro-apps. We still want developers to be able to browse the entire site in their local development environment even when all of the React applications are independently developed and deployable. Enabling this mode means that most or all of the local site has to be able to run in “static mode,” similar to a quality assurance (QA) environment. So this milestone not only allows us to break up this mega project but also increases developer productivity while we journey towards the end goal.
How we made it happen
As mentioned in the introduction, this entire endeavor is about replacing the existing infrastructure while it’s still running. Our goal is zero downtime due to bugs or rollbacks. This means that we have to move in smaller phases than if we were just building it greenfield. Phase 1 of this project introduced the concept of “static mode,” but it was disabled by default and it was all-or-nothing; you couldn’t single out specific apps. Once we tested and verified everything was working, we enabled “static mode” by default in Phase 2. After that was successful in the wild, we added “single-application mode” (SAM) in Phase 3.
Phase 0: CI setup
Before anything began, we needed to augment our current CI setup in Jenkins. To run in “static mode,” we decided to use the production assets built for our CI server in our development environment. This way, developers could easily replicate the information in our QA environment within their development environments.
When the code is merged to master, a Jenkins job builds the production assets and uploads a tarball (a package of files compressed with gzip) to the cloud with the build id in its name. Every hour, the latest tarball is downloaded and unpacked on a specific QA machine to create our CI environment.
That tarball is massive because it includes every bit of CSS and JavaScript for the entire site. It takes many minutes to download and unpack the tarball, so we couldn’t use it to seed our development environment. Instead, we created a new tarball of just our React bundles for quicker downloading and unpacking.
Phase 1: All dynamic by default
Then we began building the actual system. It relies on a git-ignored settings.json file that has a configuration for how the system should work:
{
"apps": null,
"buildIdOverride": "",
"__lastSuccessfulQABuildTime": "2018-06-22T21:31:49.361Z",
"__lastSuccessfulQABuildId": "12345-master-cfda2b6"
}
Every time the react container starts, it reads the settings.json file and the apps property that indicates static versus dynamic mode. If the settings.json file doesn’t exist, it gets auto-created with null as the value for the apps property. One or more app names within the apps array means dynamic mode, while an empty array means static mode, and null means use the default.
If the settings file indicates static mode, we retrieve the latest QA tarball stored in the cloud and unpack it locally where the Webpack compiled bundles would have been. We choose the latest build on QA instead of the HEAD of master so that what’s running locally will match what’s currently running on QA. The __lastSuccessfulQABuildTime and __lastSuccessfulQABuildId properties are logging information written out in static mode to help with later debugging.
Now, instead of running webpack-dev-server, we just run a static Express server to serve all of the static bundle assets. Because our server-side React renderer is already reading bundles written to disk by the second Webpack process, it doesn’t have to change at all because now those bundles just happen to come from the tarball.
Here’s the gist of the Docker start script:
(async () => {
// create settings.json file w/ default settings if it doesn't exist yet
await ensureJSONFileExists(SETTINGS_PATH, DEFAULT_SETTINGS);
// fetch prebuilt bundles from cloud, use `--no-fetch` to bypass
if (!process.argv.includes('--no-fetch')) {
try {
await spawnProcess('yarn fetch:static');
} catch(e) {
console.log(e.message);
process.exit(e.statusCode);
}
}
if (shouldServeDynamic()) {
// run webpack in normal development mode
spawnProcess('yarn dev');
} else {
// run static server to serve prebuilt bundles
spawnProcess('yarn serve:static');
}
})();
A developer can also select a specific tarball with the buildIdOverride property instead of using the most recent QA tarball. This is a rarely used feature, but comes in handy when needing to test out a release candidate (RC) build (or any other build) locally.
The key with this phase was minimal disruption. To start things off, we defaulted to dynamic mode, the existing way things worked. If any app was listed (i.e. apps was non-empty), we would run all the apps in the dynamic mode, using Webpack to compile the changes.
When this released, everything worked the same as before. Most folks didn’t even realize that the settings.json file was being created. We found some key stakeholders to explicitly enable static mode and worked out the kinks for about a week before moving on to Phase 2.
Phase 2: All static by default
After we felt confident that the static mode system worked, we wanted to make static mode the default, the huge win for the backend engineers. First we announced it in our weekly Frontend Guild meeting and asked all the frontend developers to start explicitly listing the names of their app(s) in the apps property within the settings.json file. This way when we flipped the switch from dynamic-by-default to static-by-default, their environment would continue to run in dynamic mode.
{
"apps": ["playground"],
"buildIdOverride": "",
"__lastSuccessfulQABuildTime": "2018-06-22T21:31:49.361Z",
"__lastSuccessfulQABuildId": "eventbrite-25763-master_16.04-c1d32bb"
}
It was at this point that we wished we had a feature flag or rollout system for our development infrastructure, like the feature flag system we have for the site where we can slowly roll out features to end users. It would’ve been nice to be able to turn on static-by-default to a small percentage of devs and slowly ramp up to 100%. That way we could handle bugs before they affected all developers.
Without such a system, we had to make the code change that enabled static mode as the default and just hope that we had adequately tested it! Now any developer who hadn’t specified an app name (or names) in their settings.json would get static mode the next time their React container restarted. We ran into a few edge case problems, but nothing major. After about a week or two, we resolved them all and moved on to Phase 3.
Phase 3: Single-application mode (SAM)
Single-application mode (codenamed SAM) was the actual feature we wanted. Instead of having to choose between all-dynamic or all-static, we started reading the apps property to determine which apps to run in dynamic mode while leaving the rest in static mode.
Before in all-dynamic mode, we determined the entry points by finding all of the subfolders within the src folder that had an index.js entry point. Now with single-application mode, we just read the apps property in settings.json to determine the entry points. All other apps are run in static mode.
/**
* returns an object with appName as key and appPath as string value to be consumed by webpack entry key
*/
const getEntries = () => {
const appNames = getSettings().apps || [];
const appPaths = appNames.map((appName) => path.resolve(__dirname, appName, 'index.js'))
.filter((filePath) => fs.existsSync(filePath));
if (_.isEmpty(appPaths)) {
throw new Error('There are no legitimate apps to compile in your entries file. Please check your settings.json file');
}
const entries = appPaths
.reduce((entryHash, appPath) => {
const appName = path.basename(path.dirname(appPath));
return {
...entryHash,
[appName]: appPath,
};
}, {});
return entries;
};
Before single-application mode, we ran a simple Express server for all-static and webpack-dev-server for all-dynamic. With SAM we have a mixture of both modes. However, we cannot run both servers on a single port. So we decided to only use webpack-dev-server and add middleware that would determine whether or not the incoming request was for an app running in dynamic or static mode. If it’s a static mode request, we just stream the file from the file system; if it’s a dynamic request we route to the appropriate webpack-dev-server using http-proxy-middleware.
const appNames = getSettings().apps || [];
// Object of app names and their corresponding ports to be ran on
const portMap = appNames.reduce((portMap, appName, index) => ({
...portMap,
[appName]: STARTING_PORT + index,
}), {});
// Object of proxy servers, used to route incoming traffic to the appropriate client dev server
const proxyMap = appNames.reduce((proxyMap, appName) => ({
...proxyMap,
[appName]: proxyMiddleware({
target: `${SERVER_HOST}:${portMap[appName]}`,
}),
}), {});
// call each workspace's <code>yarn start</code> command to kick off their respective webpack processes
appNames.forEach((appName) => {
spawnProcess(<code>yarn workspace ${appName} start ${portMap[appName]}</code>);
});
const app = express();
// Setup proxy for every appName in settings. All devMode content requests will be
// forwarded through these proxies to their corresponding webpack-dev-servers
app.use((req, res, next) => {
const appName = path.parse(req.originalUrl).name.split('.')[0];
if (proxyMap[appName]) {
return proxyMap[appName](req, res, {});
}
next();
});
// by default serve static bundles
app.use(ASSET_PATH, express.static(BUNDLES_PATH));
// start the static server
app.listen(SERVER_PORT, SERVER_HOST);
Gotchas
Issues are likely to arise with any significant change, and the change for developers to only run their app in dynamic mode was huge. Here are a couple of issues we encountered that you can hopefully avoid.
The Common Chunk
Because all of our different apps were just entry points in one big monolith app, we were able to leverage Webpack’s CommonChunkPlugin to create a shared bundle that contains the common dependencies between all of the apps. That way when our users moved between apps, after visiting the first app, they would only have to download app-specific code. Even though this is a production optimization, we built the common chunk in our development environment with webpack-dev-server as well.
Unfortunately, the common chunk broke when multiple apps were specified. Although it’s called SAM (single-application mode), the system supports specifying multiple applications that developers would like to run in dynamic mode simultaneously. While we tested that multiple apps worked in SAM, we did the majority of our testing with just one application, which is the common use case.
We include this common chunk in the tarball that gets downloaded, unpacked, and read in static mode. However, when running two apps in dynamic mode, the local common chunk would only consist of the commonalities between the two apps, not all 30+. So using the statically built common chunk caused errors in those apps running in dynamic mode.
Our initial fix was to update the webpack-dev-server middleware to also handle requests for the common chunk. However, this swung the pendulum in the opposite direction. It fixed the common chunk problem for multiple dynamic apps, but now all of the static apps were no longer using the statically built common chunk. They were using the locally built dynamic common chunk. So now all the static apps were broken.
In the end, since the common chunk is a production optimization, we elected to get rid of it in dynamic dev mode. So now no matter how many apps a developer specifies in the apps property of the settings.json, they won’t get a common chunk. However, we still need to keep the common chunk for the static mode apps for now, since the QA environment builds the apps where the common chunk still exists.
“Which mode am I in?”
Another issue we ran into wasn’t a bug, but a consequence of introducing static mode: developers didn’t know which mode they were in. Some backend developers weren’t even aware there was a static mode to begin with; they would try to make changes to an app and wonder why their changes weren’t being reflected. The problem was exacerbated when we introduced SAM in Phase 3 because one app would update while another would not. The Frontend Platform team found ourselves troubleshooting a lot of issues that ultimately were rooted in the fact that the engineer didn’t know which mode they were in.
The solution was to add an overlay message to the base HTML template that all the apps shared. It reads the settings.json file and determines which mode the currently displaying app is in, including the app name. If the app is in static mode it mentions how long it has been since its last refresh.
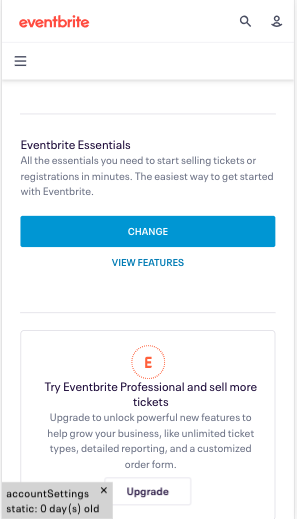
If the app is in the dynamic mode, it says “webpack dev mode.”

It turned out that mentioning the app name was also crucial because if a dev needed to work on a page that wasn’t their own, they wouldn’t always know which app needed updating.
The results are in
Our hypotheses about the benefits of the project panned out. We started hearing fewer and fewer issues from our backend engineers about the React container failing to boot. Less troubleshooting meant more time for development. Unfortunately, we don’t collect any metrics on individual engineers’ development environments so we don’t have any hard numbers on how much faster the container booted before nor the decrease in memory usage.
The biggest win for the frontend engineers was the reduction in Webpack recompile time when making changes to files. Previously Webpack traversed through all of the entry points, and now it only has to look at one (or however many the developer indicates in settings.json). The rebuild time was 2x or 3x faster, and we received lots of positive feedback.
So even though the SAM project was just a milestone in the overall endeavor to enable Micro-Apps, we were able to deliver lots of value to teams in the interim.
Coming up next
Late last year we started hearing some mysterious, but sparse reports from one or two frontend engineers that at some point Webpack would stop rebuilding when they were making changes. Over time as the engineering team added more apps and more Docker containers, the problem grew to affect almost all frontend engineers. It was even happening to us on the Frontend Platform Team.
We suspected it to be a memory issue, but we weren’t sure the source. We crossed our fingers hoping that the SAM project would fix the issue, but we were still able to trigger the problem even when only running a single app. Things were still on fire, and we realized that we couldn’t move forward with the quest for Micro-Apps until we resolved the instability issues. Any new features wouldn’t have the desired impact if the overall system was still unstable.
In the third post in the series, I will cover this topic in detail. In the meantime, have you ever managed a similar system? Did you face similar challenges? Different challenges? Let us know in the comments or ping me directly on Twitter at @benmvp.